This post was originally written for the engineering blog of my employer, Smartbox Ltd., who are also the source of the content. The original is available at https://medium.com/smartbox-engineering/releasing-software-from-chaos-to-sanity-12fcdc563e93
This article is about how, at Smartbox, we improved our release process over a period of around 2 years, going from ad hoc releases, with little structure and performed outside of business hours, to having fully managed processes and releasing during the day, only reverting to releasing outside of office hours if absolutely necessary.
When I joined, we had 2 teams doing releases of our public facing e-commerce website, each containing between 7 and 10 developers and testers, reporting to a Web Manager. One team looked after the e-commerce site, while the other took care of people who received one of our boxes as a gift. Now, there are around 8 different teams who could potentially release to the public website, as well as other teams releasing various ancillary micro-services.
Chaos
This story begins around 2015, when I joined Smartbox. At that time, we were a much smaller organization (~280 people in total, vs. 600+ today). The teams working on the platform worked in 2–3 week sprints and would do a release at the end of each.
Process
A team would get in touch with the Web Manager as they approached the end of a sprint and had a release candidate ready to go out. There was rarely any scheduling conflicts, so he would just say ‘OK, go live on Wednesday’ or similar. The release process would start going to pre-production during the day, followed by production at around 10 PM (everyone working remotely from home). When ready to begin on production, we would put the site behind a maintenance page, start the deploy (including any extra required steps), kick off the regressions and do manual UAT on production. To finish up by midnight was a rarity, but usually, we would be done by 2 AM, at which stage we would remove the maintenance page and go to bed.
It should be obvious that there were a number of issues with this:
- When there were issues and the release dragged on, people would get tired and ‘just want to finish’
- After the release was deployed, everyone would just go to bed and no further monitoring took place, which could lead to nasty surprises for your colleagues the next morning
- There wasn’t a full set of engineers and management for support during the release if there was an issue
- Why duplicate the UAT effort, when it was already done twice on a project and pre-production environment
On top of all this, there was no record of a release. The codebase is versioned with git tags but there was no centralized list detailing what was in each release, what team did it, issues encountered, etc.
Release Plan
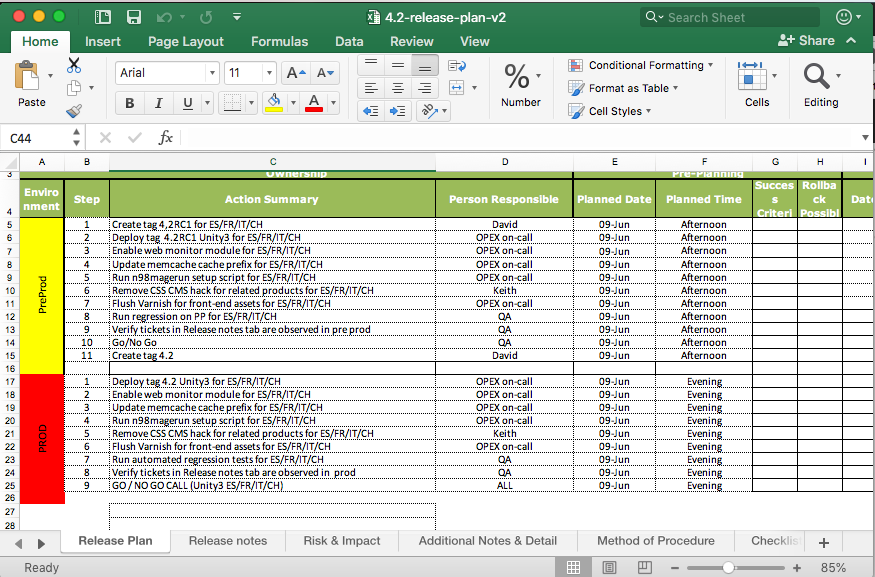
Each release would have (and still has) a release manager, to coordinate all the steps involved in deploying code. In preparation for a release, the manager would fill out an Excel spreadsheet of all the steps for pre-production and production; this was the Release Plan. Often certain tasks need to be carried out on the production server, and these would be done by an infrastructure engineer, so the Release Plan would have the extra info for them. This plan would just be emailed/shared via chat to whoever needed it and would essentially then be lost forever after the release. This also made it hard for a new release manager to come along, as they had no frame of reference for the Release Plan
While we’ve always had a suite of unit tests, it was up to the developer to run them locally and ensure nothing had broken. However, sadly the tests weren’t always run and there were instances where we would release code with a simple unit test bug in it.
We also had no way of tracking database changes, or what state the database was in. In Magento (which is what our e-commerce platform is based on), to do a DB change, you write a script called an installer. The installers are versioned in Magento, so it’s possible to tell what state the DB is in by looking at the current version of each installer. Often, when deploying, either the installer wouldn’t run, or there would be a DB refresh on pre-production and various other issues. This resulted in a lot of lost time trying to figure out why various functionalities were broken. We had no way of definitively and easily saying ‘this is what the database should look like’ after a deploy.
Summary
- Infrequent, nighttime releases
- Nothing was tracked or centralized
- Buggy code got released
Improvements
The company knew it was about to expand its workforce massively over the next few years, since it was acquiring competitors and had big plans to build a brand new back-office infrastructure. More development teams was always going to result in more releases, so it was pretty evident that we were going to need a new process whereby there could be a release every day or even multiple releases on the same day.
Additionally, not all these teams would be working on the same codebase. This enabled a relaxing of the restriction that one team could release per day. However, we still needed more control over who released what and when
Process
We started by having a weekly meeting on Fridays, where the Manager or Tech Lead of each team looking to release the following week would attend, explain what they were releasing and when they wanted to do so. The meeting was coordinated by the ‘gatekeeper’, although that phrase never really caught on! It was all very analogue and manual, involving hand-drawn calendars, lots of (amicable) discussion and the gatekeeper keeping track of everything. When everything was decided, an email would be sent out with the plan for the following week.
Another improvement we made at this time was to begin releasing during the day. We realized the maintenance wall was overkill for most releases, especially ones that weren’t changing the structure of the databases. We also reduced a lot of the required UAT, since it had already been done on a different environment, so it was a pointless duplication of effort.
Move to gitlab, Continuous Integration/Continuous Deployment
It was at this point also when we moved from doing everything in Git via the command line to having our entire codebase hosted in gitlab. This meant building a release candidate would be as simple as clicking a ‘Merge’ button for each ticket in your upcoming release. Other tasks like merging to master, creating a tag, resolving conflicts could all be done via clicks of the mouse.
Moving to gitlab also enabled us to begin initial attempts at CI/CD. As mentioned above, often a developer would commit PHP code on a feature branch that broke a PHP unit test. To alleviate this, we built pipelines in gitlab so that when a branch was pushed, we would run the unit tests in a docker container and only when the pipelines were successful could a feature branch be merged into a release branch.
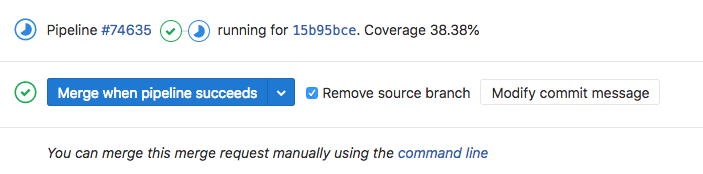
Once we had that pipeline in place, we were able to add other pipelines, e.g. to generate our zipped up Javascript app.min.js file, a PHP Composer run and we even started to work on a front end unit test suite using Karma and PhantomJS.
Release Plan
Around this time, we moved away from our in-house wiki and started using Atlassian’s Confluence instead. This allowed us to create a Release Plan Template, which could be used as a basis for all Release Plans. In this template, we added every single conceivable step that could be requested during a release, with all the extra information in the one document. So, when someone started doing a release, all they would have to do is create a new file using the template and generally remove steps. Obviously, anything very specific to that person’s release could also be added in as appropriate.
Using these Confluence templates also meant that we now had a single source for all release plans and they could be shared with a URL, worked on at the same time and kept up-to-date.
Summary
- Daily releases, weekly release planning meeting
- Use of gitlab, pipelines for verification and asset generation
- Standardized and centralized release plans
Sanity
Process
As we continued to grow, the company hired a Change Manager, with a proper background in change management. This Change Manager is still in place today and closely follows all releases throughout the company, to make sure they’re progressing, there are no clashes and that everything stays organized. Several chat rooms around release coordination, production issues and the like were created, which helps people collaborate on who’s doing what and when.
We started using a system called Service Desk to track all changes, or Production Change Requests (PCR) as they’re called. An advantage here is that a record of ALL changes are maintained, with issues and resolutions attached, so it’s very easy to go back and see what happened, and most importantly: what was the solution, if an issue re-occurs.
Finally, we introduced a morning standup, called the Change Advisory Board (CAB) where people talk about what they’re hoping to do over the current and following day, as well as discussing any on-going production issues.
So, we’ve gone from ad hoc releases to having the following well-established process:
- Build your Release Plan
- Outline your change in a PCR on day-2 (or earlier!)
- Go to the CAB on day-1
- Announce you’re ready to release in a chatroom on your go-live day
- Start releasing when you’ve got confirmation it’s OK to proceed
If one does encounter issues while releasing, these are also now tracked in the Release Plan, along with any corresponding tickets that are raised for other teams to fix. Every Monday morning, there is a meeting to discuss issues teams faced the previous week and to ensure these are being resolved by the Operations team. This ensures we don’t keep facing the same problems (repeat offenders) when releasing and that problems do actually get fixed.
Release Plan
Not much has changed in the Release Plan. The overall structure has evolved into different sections, we track the timings for each step, as well as issues encountered, as mentioned above. We also include results from automated tests, which helps to see if an issue has occurred before.
Summary
- Have a dedicated change manager
- Centralize and track ALL changes
- Communicate everything you’re doing in a standard way
Dreaming?
Ultimately we would like to move to a true Continuous Integration set-up, whereby when you finish a ticket, you simply merge to master and everything from there is automatic. We would move away from having Production and Pre-Production servers, to having a Blue/Green set-up, where both are Production-ready and it’s simple to flip between the 2. The release process would then consist of a developer doing the following:
- Merge branch to master
- This kicks off running the unit tests
- Deploy master to ‘blue’ server on success
- Run the regressions
- Flip ‘blue’ and ‘green’ servers on success, so blue is now serving the code and includes the branch just merged
We’ve put a certain amount of this in place, with gitlab and the pipelines, but we’ve some way to go before we achieve this dream scenario.
TL;DR even the summaries
- Centralize and track ALL changes!
- Automate as much as possible (pipelines, unit testing)
- Communicate in a standard way (i.e. have a fixed place/process to announce what you’re doing)
No Comments
Leave a reply
You must be logged in to post a comment.